検索のしくみ
ネット上には、さまざまな検索サービスが展開されている。

 図は、左から順に、Goo、Yahoo、Google の検索トップページである。
図は、左から順に、Goo、Yahoo、Google の検索トップページである。
君は通常、そのサービスを利用しているだろうか?
何気なく使っている検索サービスは、2つの仕組みによって、支えられている。
それは、
A:インターネット上の情報を集める
B:ユーザの求める情報を提供する
という仕組みである。
インターネット上の情報を集める仕組みは、検索ロボット(サーチロボット:search robot)と呼ばれる。
また、ロボットが集めてきた情報をためておき、ユーザの要求にあうページを表示する仕組みを、
検索エンジン(サーチエンジン:search engine)と呼ぶ。
■◇■検索ロボット
検索ロボットは、世界中からWebページ情報を集めてくる仕組みであり、
そのために作成されたプログラムを、スパイダー(Spider:蜘蛛)あるいはクローラー(Crawler:這うもの)という。
世界中にある Webサーバアクセスし、そこにあるWebページをごっそりコピーするものもあれば、
選択的にコピーするものもある。
そこで集められ、作成元の企業に送り替えさえたページ情報は、検索エンジンにより、データベース化される。
■◇■検索エンジン
多量の情報を整理し、いつでも取り出せる状態にしたものを、データベース という。
検索エンジンは、スパイダーから送られてきたWeb情報を、インデックスを付けて、データベースに登録する。
登録されたWebページは、キャッシュ とよばれる。
さらに検索エンジンは、そのデータベースの中から、Webページを探し出す仕組みを提供する。
その方法により検索エンジンは、ディレクトリ型 と 全文検索型 に分けられる。
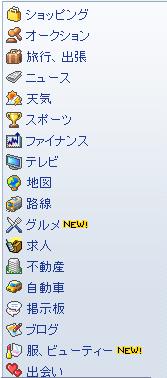 ・ディレクトリ型検索エンジン
・ディレクトリ型検索エンジン
このタイプの検索エンジンは、集められたWebページを、一定のルールで評価(審査)し、
そのルールにあったページを、ユーザの使いやすいような領域に分類して、登録する。
ユーザは、その領域(カテゴリー)を選びながら、目的のページを探し出す。
このような検索方法を、カテゴリー検索 という。
右図は、カテゴリー検索の カテゴリ一覧である。
・全文検索型検索エンジン
このタイプの検索エンジンは、集められた膨大な量のWebページに含まれる言葉を
ほぼそのままインデックスし、キャッシュする。
ユーザは、探しだしたい情報に関連する言葉を使い、検索する。
このような検索方法を、キーワード検索 という。